Avinash KanumuruBuilding a Modern Data ArchitectureThe world has moved from databases, and data warehouses to data lakes, data mesh, and data fabrics.·3 min read·Dec 12, 2023----
Avinash KanumuruinTowards Data ScienceScikit-learn Pipeline Tutorial with Parameter Tuning and Cross-ValidationIt is often a problem, working on machine learning projects, to apply preprocessing steps on different datasets used for training and…·4 min read·Aug 16, 2021--1--1
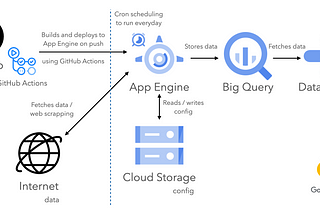
Avinash KanumuruinGeek CultureDeploy to Google App Engine using GitHub Actions (CI/CD)Continuous Integration and Continuous Deployment (CI/CD) is the core thing in MLOps (other being Data Version Control) and we will look at…4 min read·Jul 8, 2021--1--1
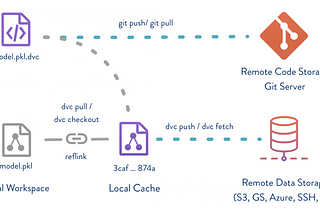
Avinash KanumuruinGeek CultureData Version Control (DVC) with Google Cloud Storage and Python for MLData Version Control is an upcoming area necessary for faster implementation of machine learning iterations and still track the changes in…·5 min read·Jun 13, 2021--2--2
Avinash KanumuruMy Tech Stack for Data Science Projectswhy I chose Python and Visual Studio Code for my data science projects…8 min read·Feb 8, 2021----
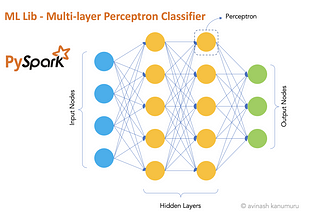
Avinash KanumuruinThe StartupPySpark’s Multi-layer Perceptron Classifier on Iris DatasetBuilding a Neural Net on Iris dataset using PySpark’s Multilayer Perceptron Classifier5 min read·Feb 5, 2021--1--1
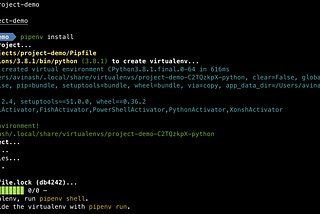
Avinash KanumuruinGeek CultureSetting up python environment in macOS using Pyenv and PipenvWe often have a problem when working on different projects in local system·5 min read·Feb 4, 2021--2--2